
【实战】调用企业微信群机器人接口实现活动经营数据自动播报
阅读(6167)
企业微信是腾讯微信团队为企业打造的企业通讯与办公工具 ,随着不断的开发完善,企业微信的功能也越来越丰富。 企业微信2.8.7新版本上线了“群机器人”功能:支持在内部群聊中添加“群机器人”,通过配置可以让机器人自动推送消息,而且还可以发布机器人到公司其它群供更多同事使用。群机器人能减少重复工作,精准提供数据支持,具有行监控告警、数据推送、构建通知、用户反馈、上线知会等功能。 下面就介绍一个我自己用python调用企业微信群机器人接口实现公司课程邀约情况的数据跟进播报案例。
要实现的功能是:根据EXCEL表的课程行事例(每月更新,包含课程及开课日期、地点、邀约目标等信息),然后从OA里读取相应的签到表数据,数据根据特定的格式处理后,调用企业微信机器人接口,播报到公司相关的不同的群里。下面开始具体的步骤:
1、添加一个企业微信群机器人:选中企业微信的某个群,右键->添加群机器人,自己设置一个名字,就添加好了一个群机器人,会显示在群成员的下面。
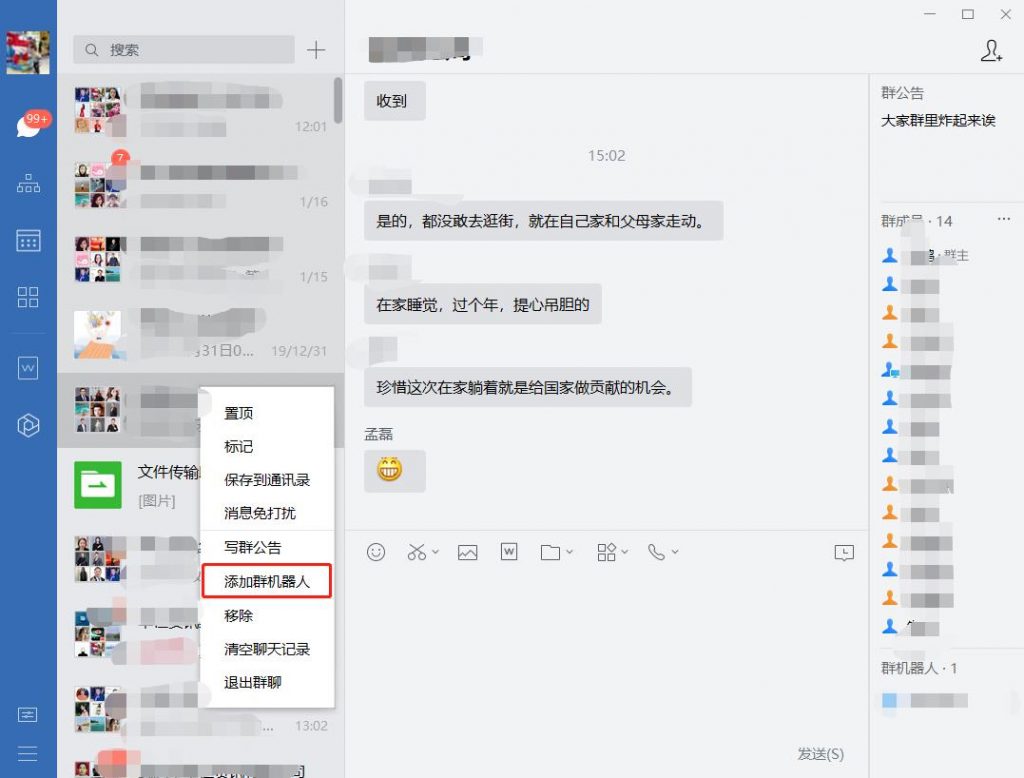
2、获得Webhook地址:将鼠标移动班新建的企业微信群机器人上就可以看到Webhook地址,点击这个地址就可以打开。
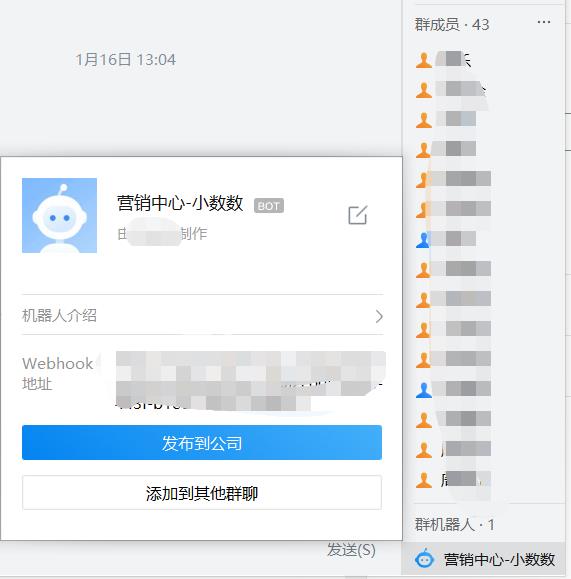
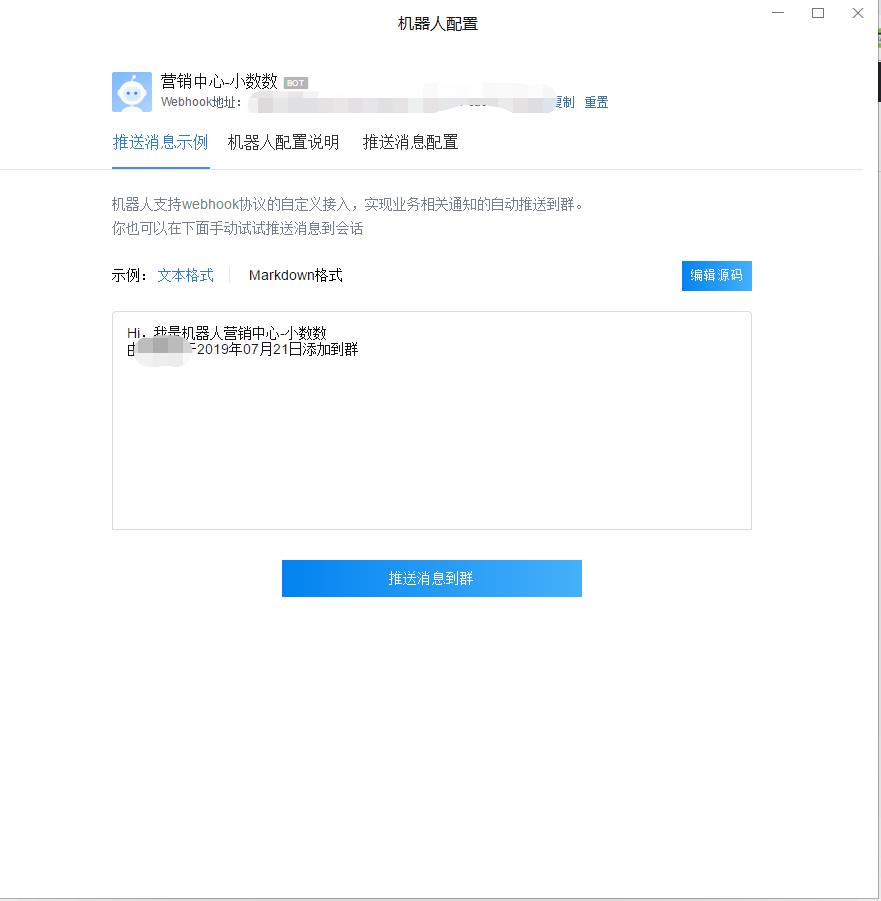
3、有了企业微信Webhook接口,接下来就是利用python读取OA数据,先导入相关库。
import requests from bs4 import BeautifulSoup from urllib import parse import numpy as np import pandas as pd import os import sys import math import datetime import calendar import re import json from selenium import webdriver import time
4、设置请求头headers及需要经常用到的常量。
#查询签到表的url,kechensel=后面数字可以参照上面进行修改,进而查询不同课程的签到表。
base_dituban='http://oa.xxxxx.com/general/sr/dke/qiandao.php?textfield1=&textfield2=&textfield3=&kechensel=50&listsearch=%B2%E9%D1%AF'
base_celeiban='http://oa.xxxxxx.com/general/sr/dke/qiandao.php?textfield1=&textfield2=&textfield3=&kechensel=25&listsearch=%B2%E9%D1%AF'
headers={
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36',
}
account_name = "xxxxx"
password = "xxxxx"
5、登录到OA获取登录后的cookies,并保存到txt文件,以备后面调用。
def get_login():
# 用webdriver启动谷歌浏览器
print("启动浏览器,打开OA登录界面")
option=webdriver.ChromeOptions()
option.add_argument('headless')
driver = webdriver.Chrome(chrome_options=option)
driver.get("http://oa.srzxjt.com")
time.sleep(2)
print("正在输入OA的登录账号和密码......")
driver.find_element_by_id("name").send_keys(account_name)
time.sleep(3)
driver.find_element_by_id("password").send_keys(password)
time.sleep(2)
driver.find_element_by_id("submit").click()
print("登录成功")
cookies = driver.get_cookies()
# 获取cookies
cookie_items = driver.get_cookies()
#print(cookie_items)
post = {}
for cookie_item in cookie_items:
post[cookie_item['name']] = cookie_item['value']
cookie_str = json.dumps(post)
with open('cookie.txt', 'w+', encoding='utf-8') as f:
f.write(cookie_str)
print("cookies信息已保存到本地")
driver.quit()
6、获取get_login()保存的cookies,并转换成字典格式。
def get_cookie():
# 读取上一步获取到的cookies
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
return cookies
7、定义一个函数,获取当天的日期及本月的天数,用于倒计时。
def daojishi():
d = datetime.datetime.now()
year = d.year
month=d.month
today=d.day
month_day=calendar.monthrange(year,month)[1]
return today,month_day
#获取当前日期,并格式化。
def date_today():
d = datetime.datetime.now()
year = d.year
month=d.month
today=d.day
month_day=calendar.monthrange(year,month)[1]
today_f=d.strftime('%Y-%m-%d')
now_time=d.strftime('%H:%M')
return today_f,now_time
8、获取查阅具体某届签到表的跳转url。
def get_url(url,jieshu):
r=requests.get(url,headers=headers,cookies=cookies)
soup=BeautifulSoup(r.text,'html.parser')
tr=soup.find_all('tr')
tr=tr[2:]
a_url=''
for t in tr:
if jieshu in str(t):
a_url=t.find_all('a')[0]['href']
if len(a_url)>0:
real_url='http://oa.srzxjt.com/general/sr/dke/'+a_url
else:
real_url=None
#print(real_url)
return real_url
9、获得具体每届的签到表里的明细数据。
def get_data(url):
try:
r=requests.get(url,headers=headers,cookies=cookies)
soup=BeautifulSoup(r.text,'html.parser')
td=soup.find_all('td')
td=td[28:]
#print(td)
l=[]
for i in td:
l.append(i.string)
#将获得的数据列表字符串化
s=str(l)
#print('这里是'+s)
#获取最后面的总人数数据,用来作为取上面列表l最大索引用
max_z=re.search(r'总人数:(\d{1,3})人',s)
#通过正则获得人数,从而获得最大行数
num=int(max_z.group(1))
#print(num)
if num>0:
#获取签到表最后面那行汇总数据
hui_zeng=str(l[num*17:num*17+1][0]).split('(')[-1][:-2]
else:
hui_zeng=''
#获得所有签到表明细数据
l=l[:num*17]
#转为np.array数组
arr=np.array(l)
#将一维数组转换成二维数组
arr=arr.reshape(len(l)//17,17)
#构建DataFrame的标题行
columns=['序号','区域','团队','学习顾问','客户姓名','性别','职位','公司名称','联系电话','类别','成交价格','预约单号','成交单号','签到人','发码','接收','备注']
df=pd.DataFrame(arr,columns=columns)
#计算新训到场的数据
df_xinxun=df.loc[(df['类别']=='新训学员')|(df['类别']=='新训学员[共生转让]')|(df['类别']=='新训学员[转让名额]')|(df['类别']=='新训学员[赠送课程]')|(df['类别']=='新训学员[赠送课程[有效期一年]]')|(df['类别']=='新训学员[赠送课程[策送地]]'),:]
#计算已经邀约的家数
jashu=pd.DataFrame(df_xinxun.groupby('区域')['公司名称'].nunique(),dtype=np.int)
#重新定义列名
jashu.columns=['已约家']
#计算已经邀约的人数
renshu=pd.DataFrame(df_xinxun.groupby('区域')['公司名称'].count(),dtype=np.int)
#重新定义列名为"已邀约的人数"
renshu.columns=['已约人']
#合并家数人数
hebin=jashu.join(renshu)
return hebin,hui_zeng
except:
print('请确认有没有排课')
10、从EXCEL中获取本月地图班、策略班开课活动数据信息。
def get_kecheng_info():
data_kecheng=pd.read_excel('./大课行事例.xlsx')
return data_kecheng
11、调用企业微信群接口发送消息。
def qy_weixin_qunrobot(data):
# 企业微信群机器人的webhooK
#测试群的
webhook='https://qyapi.weixin.qq.com/cgi-bin/webhook/send?key=xxxxxxxxxxxxx'
headers = {'content-type': 'application/json'} # 请求头
r = requests.post(webhook, headers=headers, data=json.dumps(data))
r.encoding = 'utf-8'
return (r.text)
12、设置发送的文本,这里是以markdown的形式。
def text_data(k_time,daojishi,addr,jieshu,content,z_text,now_t):
data={
"msgtype": "markdown",
"markdown":{
"content":"第<font color="\"info\"">"+jieshu+"</font>将于"+str(k_time)[0:10]+addr+"举行,还有 <font color="\"info\"">"+str(daojishi)+"</font> 天,截止到今天"+str(now_t)+"分,OA提交新训邀约如下:\n"+content+"\n"+'<font color="\"info\"">总体邀约:</font>'+str(z_text)+".请各位伙伴抓紧邀约,已经邀约的及时在OA提交预约单。\n祝福大家:多多开单!",
}
}
return data
13、这里设置@的成员,是以text的格式。
def call_data():
data={
"msgtype": "text",
"text":{
"content":"",
"mentioned_mobile_list":["@all"]
}
}
return data
14.定义main()主函数。
if __name__ == '__main__':
#模拟登录,获得cookies的值
get_login()
#修改cookie的值
cookies=get_cookie()
#获得今天的日期
today_f,now_time=date_today()
day=datetime.datetime.strptime(today_f,'%Y-%m-%d')
#把课程行事例赋给变量kecheng
kecheng=get_kecheng_info()
for i in range(len(kecheng)):
#判断开课日期与今天的日期间隔,小于等于7天时开始播报
daojishi=kecheng.iat[i,2].day-day.day
if (kecheng.iat[i,2].day-day.day)>0 and (kecheng.iat[i,2].day-day.day)<=9:
print('开始播报'+kecheng.iat[i,1]+kecheng.iat[i,0])
#获得OA具体某届课程打开的url
if '地图班' in kecheng.iat[i,0]:
real_url=get_url(base_dituban,kecheng.iat[i,0])
else:
real_url=get_url(base_celeiban,kecheng.iat[i,0])
#real_url=None
if real_url is not None:
#获得签到表里已经预约的详细数据
data_yaoyue,z_text=get_data(real_url)
#读取大课行事例里分公司制定的目标
mubiao=pd.read_excel('./大课行事例.xlsx',sheet_name=kecheng.iat[i,0])
mubiao.columns=['区域','目标家','目标人']
mubiao=mubiao.set_index('区域')
z_hebin=None
if data_yaoyue is not None and not data_yaoyue.empty:
z_hebin=mubiao.combine_first(data_yaoyue)
#把为na的值用0填充
z_hebin=z_hebin.fillna(0)
print(z_hebin)
#转换dataframe的数据类型为int
z_hebin=z_hebin.astype('int')
#重新调整各列的顺序
z_hebin=z_hebin.loc[:,['目标家','目标人','已约家','已约人']]
#按目标家这列来进行数据排序
z_hebin=z_hebin.sort_values(by='目标家',ascending=False)
data=text_data(kecheng.iat[i,2],daojishi,kecheng.iat[i,1],kecheng.iat[i,0],str(z_hebin),z_text,now_time)
qy_weixin_qunrobot(data)
call=call_data()
qy_weixin_qunrobot(call)
#print(z_hebin)
else:
print(kecheng.iat[i,0]+'没有排课')
15、全部完成后就可以通过window的任务计划,在里面设置一个定时任务,比如早上9:30,下面5:00各播报一次。
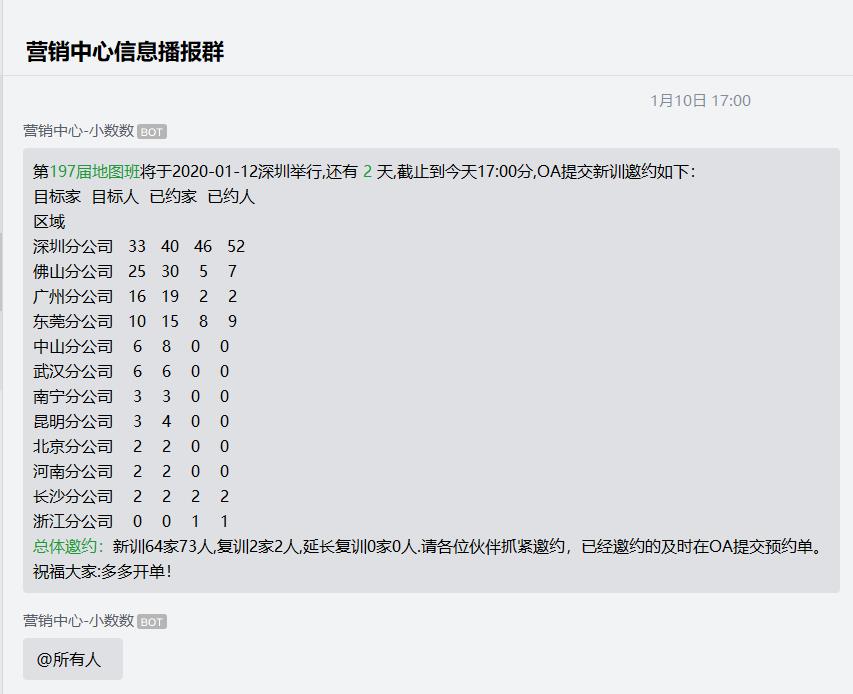
这样就可以省去人工的数据下载、导出、处理、格式化然后播报的繁琐过程,使工作更加高效、自动化,企业微信功能还有很多,而且都提供了相应的接口,下次将介绍企业微信的个性化消息群发。
由o郭二爷o原创或整理--转载请注明: http://www.dszhp.com/wxworkroot.html